








Web scraping is an approach that is used to collect information from websites. Selenium is among the top tools to accomplish this task especially in dealing with the dynamic nature of content. Selenium lets you automatize browsers and extract data from websites that require interaction from users. In this article we’ll go over the fundamentals of using Selenium to scrape web pages from setting up to dealing with complex situations such as dynamic content and proxy servers.

What is Selenium and Why Use It for Web Scraping?
It will enable websites to be automated. It can simulate user actions like pressing buttons, completing forms, or moving through the pages of a web application. Unlike other libraries in scraping, Selenium is also able to handle websites that have a lot of JavaScript and that require user interaction to download the contents. This is why it is perfect in scraping website information.
Setting Up Selenium for Web Scraping
The scraping practices demand that you enable your environment beforehand. That is the way that you can do it
2.1 Get Python and Selenium
- You can get Python at python.org.
- Install Selenium using command bash
pip install selenium
The version of WebDriver is at:
Selenium requires itself to be driven by a WebDriver to interact with browsers. To access the Chrome, visit the links under here and download the ChromeDriver and ensure the version supports a similar version of Chrome.
Set WebDriver Path 2.3
Ensure that you have WebDriver (executable) added to your system PATH or configured on your code:
python
browser = webdriver.Chrome(executable_path=path/to/chromedriver”)
Basic Web Scraping with Selenium
It is now time to scrape a site, and this is how to do it.
How to Open a Website
How to open a site with Selenium:
python
webdriver.Chrome == webdriver.Chrome()
driver.get(“[https://www.example.com]”)
The various elements can be located in a structure of a test by the following ways: Lets consider a sample structure of a test which has the various elements as shown below:
You are able to locate elements by means of such methods as find_element_by_xpath and find_element_by_id:
python
The element in the form of an h1 is driver = driver.find_element_by_xpath(“//h1”)
print(element.text)
Working with Forms and Inputs 3.3
To complete a form, use send_keys:
python
search_box = driver.find_element(name =”q”)
search_box.send_keys(‘Selenium Web Scraping’)
search_box.submit()
Handling Dynamic Content
A lot of sites implement JavaScript to dynamically load content. Selenium is capable of this by waiting on elements to appear.
Waits 4.1 Waits
WebDriverWait provided by Selenium will give you the opportunity to wait before elements appear then you can interact with them:
python
import WebDriverWait from selenium.webdriver.support.ui
import selenium.webdriver.support.expected_conditions as EC
element=WebDriverWait(driver, 10).until(
EC.presence_of_element_located(By.ID, “dynamic-content”)
)
Handling Proxies for Scraping
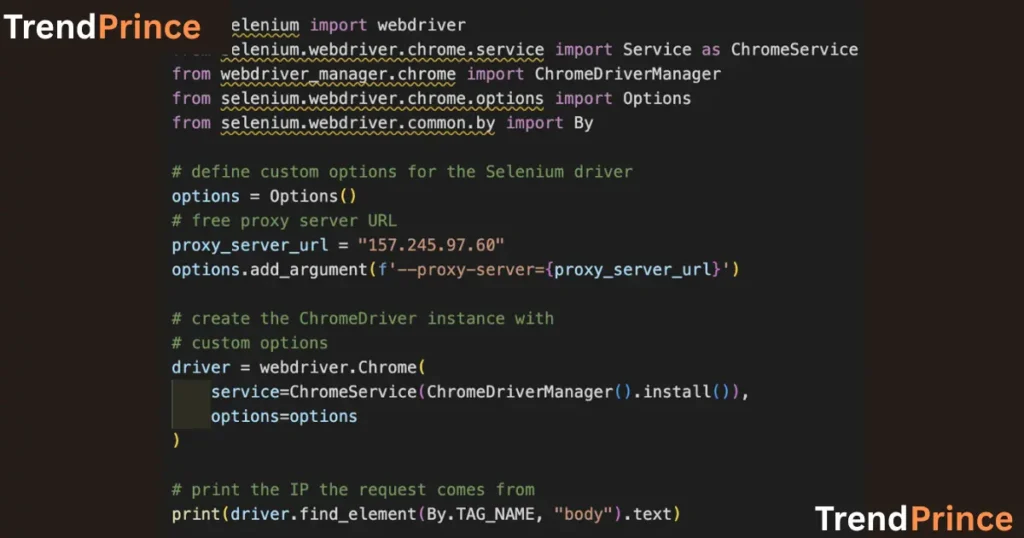
When you scrape many pages, there is a chance of having your ip address blocked. To prevent it, employ proxies.
5.1 How to configure a proxy in Selenium
With Selenium, to use a proxy:
python
chrome_options = Options()
chrome_options.add_argument(‘–proxy-server=http://your-proxy-ip: your-proxy-port’)
driver = webdriver.Chrome(options = chrome_options)
5.2 Proxies that are rotating
It is possible to rotate the proxies and not be detected using a list of proxies:
python
import random
proxies = [“http://proxy1:port”, “http://proxy2:port”]
proxy = random.chose(proxies)
chrome_options.add_argument(f’–proxy-server{proxy}’)
driver = webdriver.Chrome(chrome_options=chrome_options)
Capturing Data and Handling JavaScript
Extracting Element Text
When you have found an element, then use:
python
driver.find_element_by_xpath(“//p”).text
print(text)
JavaScript execution
You are able to run JavaScript in the browser to manipulate or access a data:
python
self.driver.execute_script(“document.body.style.backgroundColor = ‘lightblue’;”)
Working with Asynchronous JavaScript
Selenium can also do asynchronous JavaScript to wait until data loads:
python
driver.execute_async_script(“””
var callback = arguments[arguments.length-1];
setTimeout(function() {
callback();
}, 5000);
Advanced Web Scraping Techniques
Infinite Scroll
A lot of websites download more data as you scroll If you want to deal with infinite scroll, you can do scrolling with JavaScript:
python
driver.execute_script(“window.scroll(0, document.body.scrollHeight);”)
Taking Screenshots (7.2)
To make a screen shot
python
driver.save_screenshot(path = r”C:\screenshot.png”)
Security Considerations for Web Scraping
When web scraping, you must take precautions to not get blocked or even violate terms of service.
- Respect Robots.txt.
Check the robots.txt file on the websites to get information about this.
Use Random Delays 8.2
To simulate human behavior, add an unpredictable delay between calls:
python
import time
import random
time.sleep(random.uniform(1, 5)) Wait between 1-5 seconds
Rotating UA Strings 8.3
In order not to be detected, rotate the User-Agent string in order to resemble requests on behalf of different browsers:
python
chrome_options.add_argument(user_agent=’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36′)
Troubleshooting Common Issues
Element not found 9.1
In case of aNoSuchElementException, check whether the element is present, make use of explicit waits and be descriptive with your locators.
2.2 IP Blocked
Use proxies that change and insert delays to prevent detection. It can also help to implement services to break CAPTCHA code.
9.3 Page loading delays
Wait and ensure that the page is fully loaded before scraping it using waits It is also possible to extend the sleeping period or even use execute_script() to cause loading of content.
Frequently Asked Questions (FAQs)
Which one can be used to Web Scrape Selenium?
Well, Selenium is a perfect choice to web scraping especially in the case when the content is rendered dynamically using JavaScript.
10.2 What is the Way to Scrape Data with Selenium?
In order to scrape data, you would need to go to the site and find the elements you are interested in scraping and then go and grab the text or attributes using Selenium find element methods.
10.3 The way to deal with dynamic content through Selenium?
When clicking on elements, use the explicit waits (WebDriverWait) that Selenium provides to make sure the element has completely loaded and then use it.
Conclusion
Selenium is a dynamic web scraping tool particularly in case of dynamic websites. It can interact with pages, manipulate JavaScript content and be able to use proxies, which makes scraping of complex sites very simple. Based on the direction presented in this tutorial, you can successfully install Selenium to scrape web pages quickly and manage some issues, such as IP blocking, CAPTCHAs, and dynamic pages.
Comments